本文主要对人工智能的神经网络相关理论进行介绍与分析,并将LSTM与GRU结合形成的LG神经网络模型用于股票预测,并进行了程序编程设计的实践验证和案例分析。
 爱校码
爱校码
致力于少儿编程与软件工程的信息分享
一、神经网络的相关理论
人类不是每一秒都从零开始思考的,从诞生之日,从一无所知,经过了幼儿学前教育、幼儿园教育、小学、中学、大学、研究生等教育阶段,除了掌握通识的知识以外,还掌握了某一领域的专业知识而成为博士或专家。从此以后,人类依据既有的知识进行思维,来推理未知的领域探索并创新。
人工神经网络(Artificial Neural Network,ANN)简称为神经网络,它是一种受到了人类脑神经系统的工作方式启发,从而建立起来的数学模型。不过,人类脑神经系统是一个由生物神经元组成的高度复杂的生物综合系统,其为一个并行的非线性信息处理系统,可以将听觉、视觉等获取的信息经过多层的编码,从最原始的低层特征不断加工、抽象,得到了原始信息的语义表示。与人脑类似,神经网络是由人工神经元以及神经元之间的连接构成。有两类神经元,其一是输入,用来接收外部的信息;其二是输出,即输出信息。可以将神经网络看作是具有输入与输出的信息处理系统。
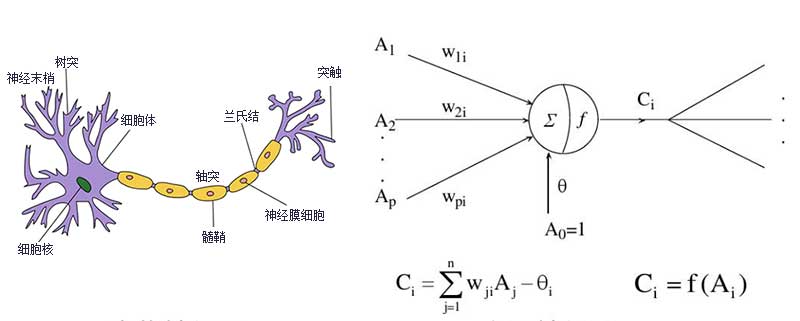
将神经网络看作是由一组参数控制的函数,其参数可以通过机器学习的方式来从数据中学习。由于神经网络模型一般较复杂,从输入到输出的信息传递路径也较长,所以复杂神经网络的学习是一种深度的机器学习,即深度学习(Deep Learning,DL)。
1. 人工智能
人工智能(Artificial Intelligence,AI)就是让机器具有人类的智能。它是计算机科学的一个分支,主要研究、开发用于模拟、延伸和扩展
人类智能的理论、方法、技术及应用系统。让计算机的机器行为看起来就像是人类所表现出的智能行为,其分为感知、学习、认知几个方面,感知即模拟人类的感知能力,对外部刺激信号进行处理,包括语音、计算机视觉信息处理;学习即模拟人类的学习能力,从样例数据或者与环境交互中进行学习,包含监督学习、无监督学习以及强化学习;认知即模拟人类的认知能力,包含知识表达、自然语言理解、推理、规划、决策等领域。
人工智能从诞生至今,由于计算机科学的发展与计算机处理能力的飞速变迁,人工智能也伴随着跌宕起伏,经历了一次又一次的繁荣与低谷,其发展历程经历了推理期、知识期和学习期的阶段。
推理期基于逻辑或者事实归纳出来一些规则,通过计算机程序来完成一个任务,但往往这些推理规则过于简单,难以胜任人类复杂的智能推理;
知识期基于在特定的专业领域构建专家知识库,形成了知识库+推理机的具有专门知识和经验的计算机系统,主要通过Prolog(Programming in Logic)程序语言开发专家系统(Expert System)处理一些复杂的任务。但是人类的很多智能行为,很难获知其中的原理,也无法归纳出这些智能行为背后的知识库,难以开发出知识和推理的 专家系统;
学习期基于学习本身就是一种智能行为,让机器(计算机程序)来自动学习,即机器学习(Machine Learning,ML)。计算机程序是设计学习算法,可以从数据中自动分析获得规律,并利用学习到的规律对未知数据进行预测,从而帮助人们完成一些特定任务。
2. 机器学习
机器学习(Machine Learning,ML),即从有限的观测数据中学习出具有通用性的规律,并利用其对未知数据进行预测的方法。
通常的机器学习主要是是学习一个预测模型。首先将数据表示为一组特征(Feature),其表示形式可以是连续的数值、离散的符号或其他形式, 然后将它们输入到预测模型,并输出预测结果。这类机器学习可以认为是浅度学习(Shallow Learning,SL),其特点是不涉及特征学习,这些特征主要靠人工经验或特征转换方法来获取。机器学习模型的过程包含以下几个阶段:

2.1 数据预处理
数据预处理主要进行数据的清洗,如去噪声,去除干扰数据等。
2.2 特征提取
从原始数据中提取一些有效的特征,如指纹图像识别中,提取指纹特征点。
2.3 特征转换
对特征进行一定的加工,包括特征抽取和特征选择两种途径。常用的特征转换方法有主成分分析、线性判别分析等。很多特征转换方法也都是机器学习方法。
上述流程中,每步特征处理以及预测都是分开进行处理的。传统的机器学习模型主要关注于最后一步,即构建预测函数。实际操作中,前三步中的特征处理对系统的准确性有着十分关键的作用。特征处理需要人工干预完成,利用人类的经验来选取好的特征,以提高机器学习系统的性能。因此,很多的机器学习问题变成了特征工程问题, 机器学习的主要工作量都消耗在了预处理、特征提取以及特征转换的环节。
3. 表示学习
为提高机器学习系统的准确率,需要将输入信息转换为有效的特征,称为表示(Representation)。若有一种算法可以自动地学习出有效的特征,并提高机器学习模型的性能,即此学习就可以叫做表示学习。
3.1 局部表示和分布式表示
机器学习中,经常使用两种方式来表示特征:局部表示和分布式表示。以表示颜色为例,使用不同名字来命名不同的颜色,这种表示方式叫做局部表示,也称为离散表示或符号表示。局部表示通常可以表示为one-hot向量的形式。one-hot向量为有且只有一个元素为1,其余元素都为0的向量。它经常被用于局部表示特征。另一种表示颜色的方法是用RGB值来表示颜色,不同颜色对应到R、G、B三维空间中一个点,这种表示方式叫做分布式表示。分布式表示叫做分散式表示,可能更容易理解,即一种颜色的语义分散到语义空间中的不同基向量上。
3.2 表示学习
要学习到一种好的高层语义表示,一般为分布式表示,通常需要从底层特征开始,经过多步非线性转换才能得到。一个深层结构的优点是可以增加特征的重用性,从而指数级地增加表示能力。表示学习的关键是构建具有一定深度的多层次特征表示。传统的特征学习一般是通过人为地设计一些准则,然后根据这些准则来选取有效的特征。
4. 深度学习
为了学习一种好的表示,需要构建具有一定深度的模型,并通过学习算法来让模型自动学习出好的特征表示,从底层特征,到中层特征,再到高层特征。从而最终提升预测模型的准确率。所谓深度是指原始数据进行非线性特征转换的次数。如果把一个表示学习系统看作是一个有向图结构,深度也可以看作是从输入节点到输出节点所经过的最长路径的长度。
使用一种学习方法(算法)可以从数据中学习一个“深度模型”,这就是深度学习(Deep Learning,DL)。其主要目的是从数据中自动学习到有效的特征表示。通过多层的特征转换,把原始数据变成更高层次、更抽象的表示。其数据处理流程如下:

深度学习是将原始的数据特征通过多步的特征转换得到一种特征表示,并进一步输入到预测函数得到最终结果。深度学习需要解决的关键问题是贡献度分配问题。深度学习采用的模型主要是神经网络模型,其主要原因是神经网络模型可以使用误差反向传播算法,从而可以比较好地解决贡献度分配问题。 只要是超过一层的神经网络都会存在贡献度分配问题,因此超过一层的神经网络都可以看作是深度学习模型。
以神经网络为基础的深度学习,由于大规模并行计算以及 GPU 设备的普及,在强大的计算能力和海量的数据规模模式下,可以端到端地训练出一个大规模深度神经网络模型。
5. 前馈神经网络
在前馈神经网络中,各神经元分别属于不同的层。 每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层.。最左边层称为输入层,最右边一层称为输出层,其他中间层称为隐藏层。整个网络中无反馈,信号从输入层向输出层单向传播。如图所示:
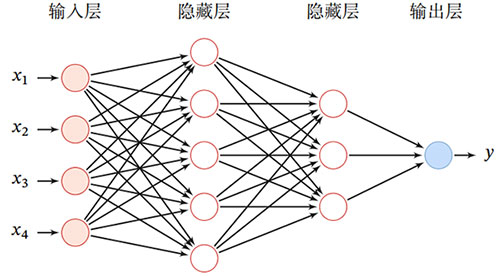
前馈神经网络的相邻两层的神经元之间为全连接关系,作为一种能力很强的非线性模型,神经元的激活函数可以使用Sigmoid型函数,并且使用的损失函数也大多数是平方损失。其作为一种连接主义的典型模型,标志人工智能从高度符号化的知识期向低符号化的学习期开始转变。
BP(back propagation)神经网络,是一种按照误差逆向传播算法训练的多层前馈神经网络,BP算法包括信号的前向传播和误差的反向传播两个过程。正向传播时,输入信号通过隐含层作用于输出节点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。误差反传是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值的依据。
6. 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN )是一种具有局部连接、权重共享等特性的包含卷积计算且具有深度结构层次前馈神经网络。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类。其结构如图所示:
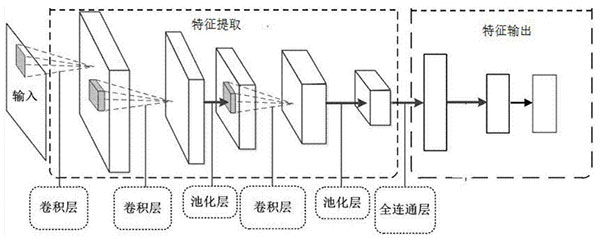
卷积神经网络已经成为计算机视觉领域的主流模型,不用预训练和逐层训练,使用了GPU 进行并行训练,极大地推动了端到端的深度学习模型的发展。
7.循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。
7.1 序列数据
常见的序列数据包括信号、文本、视频序列、股票价格等。序列中的有效信息依附于不同间隔的事件中,这些间隔或长或短,很难用通用的手段捕获其中的依赖关系。可以对整个序列的所有状态进行平均,并用这个平均状态来作为整个序列的表示。
7.2 循环神经网络
循环神经网络是专门用于处理序列数据的神经网络模型。
博文最后更新时间: